ABBYY FineReader 14 Review: Best-in-Class OCR
OPTICAL CHARACTER RECOGNITION, or OCR, is the process of a computer identifying printed characters and re-creating them digitally – so you can create, save and edit digital copies of paper notes and documents.
ABBYY’s FineReader series has arguably been the king of consumer-grade OCR software for a few years now, thanks largely to 2015’s excellent FineReader 12.
Table of Contents
FineReader 14 (we don’t know what happened to number 13 either – maybe it’s superstitious) promises improved performance and a new suite of PDF editing tools, albeit at a steep starting.
We reviewed, SMB-targeting Corporate edition, which also adds a document comparison tool and automated processing – though happily, the core paper-to-digital conversion features appear to be identical across both versions.
FineReader 14 doesn’t feel noticeably faster than its predecessor at converting documents into editable form, but it works quickly.
It takes about five seconds to digitize a two-page, mixed text and color PDF, and as in FineReader 12, you can start checking and editing the first few pages of a long document before the rest has finished processing.
PROOF, IF NEEDED
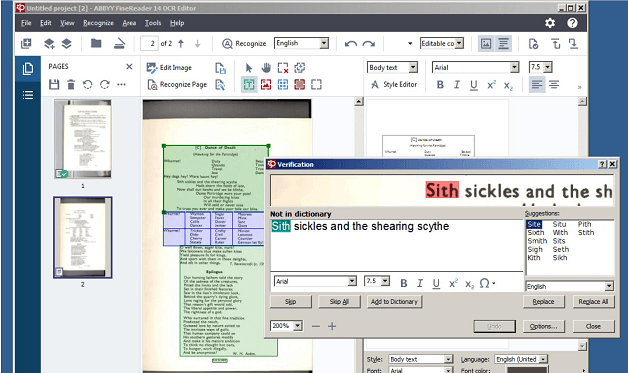
In fact, FineReader 14 does much of the work for you, with its spellchecker-like Verify tool. This highlights possible mistakes (where a character hasn’t been correctly copied across) and takes you through them one at a time, so you can quickly fix them with the basic text-editing tools.
It produces a lot of false positives, but in a way that’s the preferable outcome – it’s better for the software to be overly cautious than for it to miss errors.
It’s very handy for getting the best results when converting, say, a PDF into a Word document, but the main reason for buying OCR software is to digitise paper documents, and FineReader 14 makes this child’s play.
We simply had to place the document in our scanner, connect it to the PC, click Scan in the main menu and Scan to OCR Editor.
You can also scan directly to Word, but it’s safer to check it over in the OCR editor before saving the results as a .doc.
The processes involved with OCR mean -like speech-to-text – it is probably not going to be 100% reliable in terms of accuracy for a while.
Nonetheless, FineReader 14 impressed us by how often it got everything right.
You can compare different versions of the same document
Unsurprisingly, it works best with simple text pages, with which it performs almost flawlessly. In our tests, the biggest mistake it made was confusing a hyphen for a -»sign.
Otherwise, it accurately replicated spacing, fonts, formatting (such as bold and underlined text), small tables and other symbols.
There were no kerning mishaps (such as ‘cP being mistaken for ‘d’) either.
COPY RIGHT
It can struggle a bit more with complex documents.
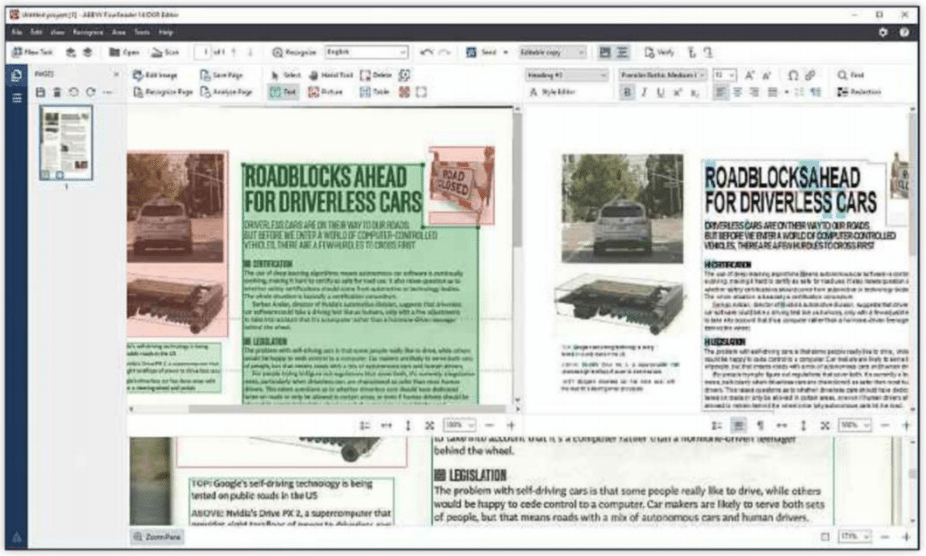
We scanned in a Shopper page with multiple text paragraphs, subheaders and colour images and there were a few mistakes in the converted file, including the headline lacking spaces between words and some small graphics of tyre tracks, which we’d used as bullet points, appearing as HI, HI, H or 8.
Otherwise, however, it was fine.
There were no nonsense words in the processed text, typeface differences were preserved and images were all in the right place.
FineReader 14 also works decently with data tables, although it’s not as good as it is with text documents.
When we tried converting a large laptop specs sheet into an Excel table, several symbols went missing and cell coloring wasn’t replicated, but the vast majority of data was still digitized accurately.
With the Verify tool, fixing the mistakes was certainly faster and less tedious than manually entering all the data would have been.
The new PDF editor was also a nice surprise.
It’s a comprehensive set of tools for what is ultimately a secondary concern to the OCR: we could add mark-up notes, text boxes and images, draw lines and shapes, redact or remove passages, insert a signature or secure the PDF with added password protection.
It’s almost on a par with dedicated PDF editing suites such as Foxit PhantomPDF, and will definitely do the job for basic touching-up and collaborative work.
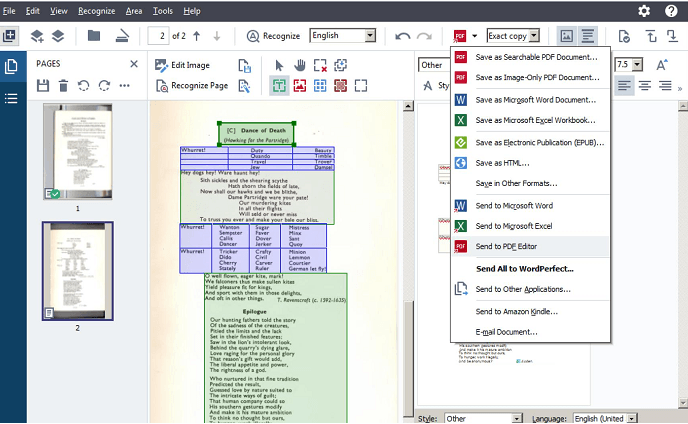
You can save the edited PDF as a Word, Excel or PowerPoint file, so you can continue working on it in more familiar software. There’s support for several other file types, such as .html, .txtm and .odt, as well.
SEARCH FOR CLUES
The Corporate edition’s Compare tool is a slightly different use of OCR: it analyses two versions of the same document and highlights differences between them.
It’s very thorough, being able to pick up inconsistencies as small as an errant comma, and makes it easy to search though differences by listing them in a panel on the right.
You can compare across different file types, too – useful for checking if the Word and PDF versions of a document are consistent, for instance.
Even image file types such as JPGs can work, as FineReader 14 will be able to read any text in the picture.
It’s fitting that this is only in the Corporate edition, as we see it being used to compare versions of vital documents such as contracts.
In fact, since the main differences between the standard and Corporate editions are the Compare tool and automated processing of larger documents, the standard edition will be a better deal for most home users.
You’ll save and will still get the meat of what makes FineReader 14 so good: accurate OCR, easy file conversions and the new editing tools.
This is a great package for home users, but gets our Business Buy award for those dealing with huge or more important documents.
James Archer
VERDICT
When you purchase through links on our site, I may earn an affiliate commission. Here’s how it works.
![ABBYY FineReader 14 Standard for PC [Download]](https://m.media-amazon.com/images/I/81a-CuimPUL._SL500_.jpg)
![ABBYY FineReader 14 Standard for PC [Download]](https://topnewreview.com/wp-content/plugins/content-egg/res/logos/amazon-com.png)
SPECIFICATIONS
- OS SUPPORT Windows 7/8/8.1/10
- MINIMUM CPU 1GHz
- MINIMUM RAM 1GB plus 512MB per additional CPU core
- HARD DISK SPACE 2.4GB



Would be more interested if they didn’t limit it to 1 PC. I have need for it “on the road”, literally, since I road rally with the Sports Car Club of America. I need it to work with my wand-style scanner on our route instructions, and it needs to be fast. Therefore it needs to work on the Laptop. But when I get home and want to work with it, I want it to work on my desktop, a large tower machine with lots of storage. That would mean 2 “standard” purchases amounting to $400. OCR is not worth $400 to me. If I could get it so I could use it on all 3 of my Windows 10 computers, like I use Microsoft Office on them, I’d be more interested.
Agreed with you. That would be great !
Btw, I really like this software. 🙂